Как устроен поиск Яндекса: о чем невозможно прочитать
Хорошо дополняет материалы лекция Дениса Нагорнова от 2013 года.
Пётр Попов. Поиск с инженерной точки зрения
Архитектура поиска
Похожа на пирамиду, состоит из этапов:
-
Обойти интернет;
-
Построить поисковый индекс;
-
Опубликовать индекс на поиск;
-
Ответить пользователю.
Обход интернета
Яндекс знает несколько триллионов урлов, обходит несколько миллиардов документов в день. Но все урлы не обойдет никогда, потому что Интернет бесконечен.
Новые документы робот в основном находит по ссылкам из обработанных документов.
Построение индекса
По данным ашмановской динамики поиска, Яндекс опережает Гугл почти в два раза по полноте поискового индекса. Такой отрыв стал возможен благодаря усовершенствованиям — закупке новых машин и оптимизации процессов.

Схема построения поисковой базы
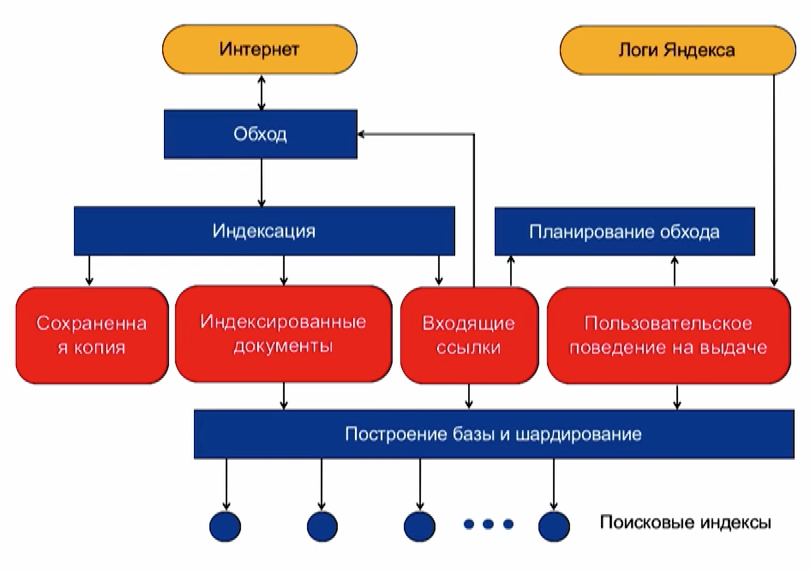
Робот обходит Интернет и индексирует документы. Кладёт их в сохраненную копию, чтобы потом показать на выдаче, например. Сохраненная копия — отдельная хэш-таблица между дата-центрами.
В процессе индексации робот извлекает слова из документа и раскладывает по леммам, видит ссылки на другие страницы и идёт дальше.
В помощь индексации также используются логи Яндекса. Если документ показан в выдаче или на него есть клик из выдачи — нужно оставить его в индексе. Логично, что и ссылки с такого документа должны вести на хороший документ.
Публикация индекса в поиск
Основная проблема — все данные обрабатываются в собственном map-reduce YTable, сокращенно Ыть. Суммарный обьём 50 петабайт.
Полное описание — на Хабре.
Проблемы мапредьюса
Мап редьюс использует батчевые операции. Для того, чтобы определить приоритетные документы для обхода, Яндекс берет весь ссылочный граф, соединяет со всем пользовательским поведением и формирует очередь для скачивания.
Процесс получается медленным, для построения индекса — тоже.
Стадии батчевые для всей базы — выкладывается или дельта или всё.
На таких объемах данных важно ускорить процедуру доставки индекса. Для этого есть быстрые контуры. Например Яндекс Новости — загрузка новостей в реалтайме и публикация для пользователя.
Схема устройства поиска

Балансеры — машины-фронты, которые генерируют выдачу.
Метапоиски — агрегируют выдачу с разных вертикалей: документов, картинок и видео. Они опрашиваются независимо.
Метапоиски — опрашивают индексы, которые разбиты на кусочки, над каждым поиск и к каждому идёт запрос.
В каждом дата-центре хранится от 2-4 копий индекса.
Сейчас всё хранится в оперативке напрямую — долго.
Ускорить можно— перевести на ССД.
Как устроен поисковый кластер

Факты в цифрах:
-
Миллионы экземпляров разных программ;
-
Тысячи типов программ, все общаются по TCP/IP;
-
Все потребляют разные ресурсы;
Все программы живут на серверах; -
Всё катается с помощью торрента.
-
Раздач больше, чем на Pirate Bay.
Что улучшают в конструкции
Механизмы
Яндекс вкладывается в развитие ядра Линукса.
Заранее планируют, как распределять программы по серверам.
Хотят объединить поисковые и роботные кластеры — нужно запускать map reduce отдельно от поисковых программ. MR ест диски и сеть, программы расходуют CPU.
Но по CPU можно и балансировать.
Матрикснет
Формула простая :) — содержит бинарные признаки документа и вычисление релеватности в цикле. Для ответа пользователю используется до 200 000 итераций.

Машинное обучение
-
Индексы для формулы подбираются полным перебором;
-
GPU работают лучше CPU, но выборки для обучения не помещаются в память;
-
Машинное обучение хотят использовать не только в деревьях выбора, но и в нейронных сетях.
Сжатие индексов
-
Хотят компрессировать последовательность ui32;
-
В Яндексе используют проприетарный алгоритм сжатия и экономят 10-15% оперативной памяти.
Мелочи

Вопросы-ответы
Проблемы роста формулы ранжирования
Раньше ранжировали на базовых поисках, на каждом отдавали 100 результатов.
Теперь лучшие 100 результатов объединяются на среднем и ранжируются еще раз более тяжелой формулой. Ресурсов занимает в 1000 раз меньше.
Первая формула ранжирования была размером в 10 байт, 100 символов.
Теперь одна формула релевантности — 100 мб.
Нереально зареверсинжинирить :)
Олег Фёдоров. Вызовы поискового облака
Конспекта нет, всё в основном хард по железу.
Александр Сафронов. Как найти лучшие ответы
Цель: рассказать о том, как улучшают качество поиска в Яндексе и какие задачи решают.
Все железки и инфраструктура нужны для поиска → ранжирования → улучшения качества поиска → профита → счастья пользователя.

Как измерять
Существует две группы измерений:
1. Оценка по асессорской разметке
Учим машину оценками людей: запрос → топ → оценки — агрегация → метрика

2. Онлайн эксперименты на пользователях, АБ-тесты.

Исключения при улучшении качества поиска
Однажды Яндекс выкатил новое ранжирование в онлайн, пользователям понравилось — все нужные параметры увеличились, за исключением одного. Новое ранжирование просадило новый блок контекста в нижнем блоке.
Яндекс сохранил новое ранжирование и пожертвовал кликами и деньгами. Ми-ми-ми :)
Что улучшать?
-
Факторы ранжирования;
-
Машинное обучение;
-
Лингвистика;
Факторы
Фактор — это число, которое описывает документ, запрос или связь документ-запрос.
Простой фактор — количество слов из запроса на странице.
~1500 факторов сейчас в веб-поиске — нужно учитывать много разных параметров, чтобы отличать хорошее от плохого в запросе.
Виды факторов
-
текстовые — покрытие, близость слов, близость к началу;
-
запросные — количество слов;
-
документные — посещаемость;
-
ссылочные;
-
пользовательские;
-
персональные;
-
метафакторы;
-
и т.д.
Существуют инструменты для оценки пользы каждого фактора.

результат проверки фактора
Фактор создают, оценивают и внедряют, если он положительный
Машинное обучение
По отдельности факторы слабые, поэтому их собирают в единую формулу, которая выдаст одно число, по которому и будут ранжировать документы в поиске.
Матрикснет
Матрикснет — совокупность алгоритмов машинного обучения, с GBRT — множеством решающих деревьев, подобранных так, чтобы суммируя значения в листьях, получать хорошее предсказание оценки релевантности, которую поставил асессор.
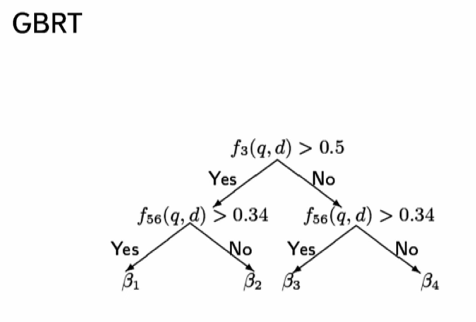
В узлах дерева — разделяющие условия, которые представляют собой проверку на числа, например фактор №50 > 0,5.
Нейронные сети
Используются, в т.ч. в поиске.

Недавно внедрили фактор на основе алгоритма DSSM — запрос и документов в виде векторов чисел с плавающей точкой, косинусное умножение которых хорошо предсказывает асессорскую оценку.
Лингвистика
Самая прикладная задача, решаемая с помощью лингвистики — расширение запросов.
Расширение запросов
Поисковая система должна понимать падежи, роды и т.д. Все это умеют, но сейчас есть вызовы уровня построить морфологию для незнакомого языка.
Синонимы
Аббревиатуры, транслиты и т.д. Всему поиск надо учить.
Связанные расширения

В примере Яндекс набирает ассоциативно связанное облако других слов и словосочетаний, других запросов, которые с каким-то весом связаны с исходных запросом.
Если документ хорошо отвечает на запрос пользователя — скорее всего будет содержать слова не только запроса, но и связанные,
Даже если слов запроса в тексте страницы нет, то по ассоциациям понятно, что страница по теме.
Как получать
-
готовые словари, но их мало для Яндекса:
-
майнинг из текстов — используют много майнеров, в т.ч. для языков, которыми не владеют;
-
майнинг из сессий;
-
+ машинное обучение для оценки.
Интересные текущие и будущие задачи поиска
-
Добавлять больше полезных сигналов через факторы;
-
Совершенствовать машинное обучение и оптимизировать производительность формул;
-
Добавлять больше хороших расширений, майнеров, гипотез.
Комментарии:
← Обзор SEO META in 1 CLICK ∙ UDC 2017: презентация →
